
- Published on
An Introduction to Explainable AI Methods
Modern artificial intelligence models, particularly deep neural networks, have achieved superhuman performance on a wide range of tasks. Yet, for all their power, they often operate as "black boxes." We can observe their inputs and outputs, but the internal logic that leads from one to the other is buried in millions or even billions of learned parameters. This opacity is a significant barrier to trust, especially in high-stakes domains like medical diagnosis, financial lending, and autonomous vehicles.
Explainable AI (XAI) is a field of research dedicated to piercing this veil. It provides a set of tools and frameworks for understanding and interpreting the predictions of complex models. XAI is not merely an academic pursuit; it is becoming a practical necessity for debugging models, ensuring fairness, complying with regulations, and building human trust. Without it, we are left to simply hope that our powerful models are behaving as intended.
Interpretability vs. Post-Hoc Explainability
Before diving into specific methods, it's important to distinguish between two key concepts:
- Interpretability: This refers to models that are inherently understandable due to their simple structure. A linear regression model, for instance, is interpretable because the learned weights directly show the importance and relationship of each input feature.
- Post-Hoc Explainability: This involves applying a technique after a complex model has been trained to explain its individual predictions. The vast majority of modern XAI research focuses on this, as it allows us to use powerful black-box models while still gaining insight into their behavior.
This article focuses on five popular post-hoc explainability methods.
A Survey of XAI Techniques
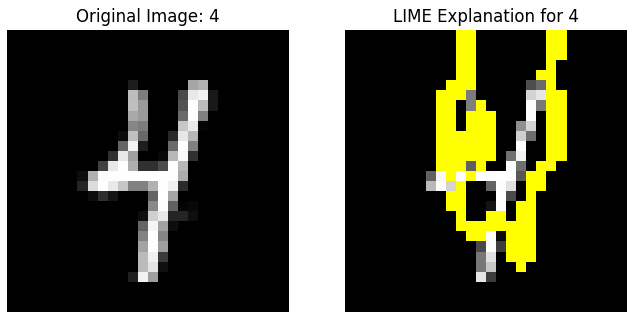
1. Model-Agnostic Surrogates: LIME
What if you can't access the model's internal gradients? Local Interpretable Model-agnostic Explanations (LIME) is designed for this exact scenario. It treats the model as a complete black box.
- Process: To explain a single prediction, LIME generates a small dataset of "neighbors" around the original input by perturbing it (e.g., turning on/off superpixels in an image). It gets the model's predictions for these neighbors and then trains a simple, interpretable surrogate model (like a weighted linear regression) that approximates the black-box model's behavior only in that local area.
- Result: The explanation is the simple model itself. For an image, it might be the set of superpixels that had the highest positive weights in the local linear model.
- Trade-off: LIME is highly flexible and intuitive but its explanations are only locally faithful and can be unstable depending on how the perturbations are generated.
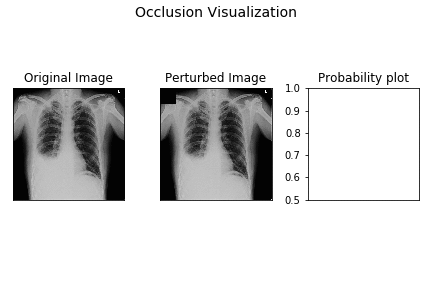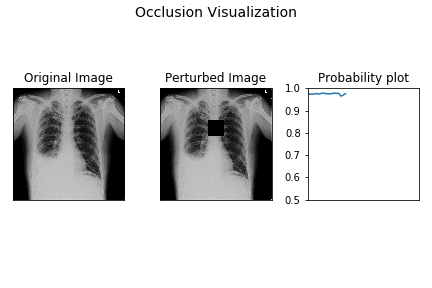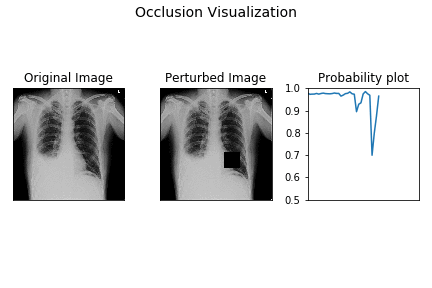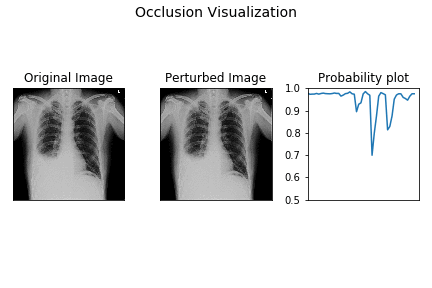
2. Perturbation-Based Methods: Occlusion Analysis
Occlusion is one of the most intuitive XAI methods. The core idea is simple: to determine which part of an input is most important for a prediction, systematically hide or "occlude" different parts of it and see how the model's confidence changes.
- Process: For an image, this involves sliding a gray or black square across it, patch by patch. At each position, you run the model and record the probability of the correct class.
- Result: By plotting the resulting probability drops, you can create a heatmap that shows which regions of the image were most critical for the model's decision.
- Trade-off: It is easy to understand and implement but can be computationally expensive, as it requires many forward passes through the model for a single explanation.
3. Gradient-Based Methods: Saliency Maps
Gradient-based methods use the internal signals of the neural network itself to generate explanations. A basic approach is the saliency map.
- Process: It calculates the gradient of the final prediction score with respect to the input pixels. This gradient tells us which pixels need to be changed the least to affect the score the most.
- Result: The absolute value of these gradients can be visualized as a heatmap, where bright pixels indicate high saliency—regions the model is sensitive to.
- Trade-off: Saliency maps are fast to compute (requiring only one backpropagation pass) but are often noisy and can be difficult to interpret, highlighting both positive and negative contributions without distinction.

4. Advanced Gradient-Based Methods: Grad-CAM
Gradient-weighted Class Activation Mapping (Grad-CAM) is a significant refinement of saliency maps, designed specifically for Convolutional Neural Networks (CNNs). It produces smoother, more class-discriminative visualizations. For a detailed guide on visualizing model predictions using techniques like Grad-CAM and Attention Maps, read my article on Visualizing Model Predictions: Attention Maps & Grad-CAM.
- Process: Grad-CAM uses the gradients flowing into the final convolutional layer of a CNN. These gradients are used to weight the activation maps from that layer. A weighted combination of these maps, followed by a ReLU activation, produces a coarse heatmap of the "important" regions for a specific class.
- Result: A localized heatmap that clearly shows the parts of the image the model focused on to make its prediction for a particular class.
- Trade-off: It produces high-quality, easy-to-understand visualizations for CNNs but is less directly applicable to other architectures like Transformers.

5. Game Theory-Based Methods: SHAP
SHAP (SHapley Additive exPlanations) is a unified approach to explainability rooted in cooperative game theory. It aims to fairly distribute the "payout" (the model's prediction) among the "players" (the input features).
- Process: SHAP calculates the Shapley value for each feature, which represents its average marginal contribution to the prediction across all possible combinations of features.
- Result: SHAP values provide a complete, theoretically grounded explanation, showing not only which features are important but also whether they push the prediction higher or lower.
- Trade-off: SHAP has strong theoretical guarantees and provides detailed explanations, but it is very computationally intensive, especially for images.
Where Do We Go From Here?
Choosing an XAI method involves trade-offs between computational cost, ease of implementation, and the quality and faithfulness of the explanation. There is no single "best" method; the right choice depends on the model architecture, the application, and the audience for the explanation.
The field of XAI is still young and faces open challenges. Explanations can be manipulated or misleading, and evaluating their correctness remains a difficult problem. However, as AI systems become more integrated into our lives, the demand for transparency will only intensify. Building models that are not only powerful but also understandable is one of the most critical tasks facing the AI community today.
Enjoyed this post? Subscribe to the Newsletter for more deep dives into ML infrastructure, interpretibility, and applied AI engineering or check out other posts at Deeper Thoughts