
- Published on
From Transformers to State Space Models
Since its introduction in 2017, the Transformer architecture has been the driving force behind the modern AI revolution. Its self-attention mechanism, which allows every token in a sequence to look at every other token, proved to be exceptionally powerful for understanding context in language. For a deeper analysis of this mechanism, read my article on "Beyond Attention". However, this power comes at a steep price: the computational and memory cost of self-attention grows quadratically with the length of the sequence (O(N²)). This has created a significant bottleneck, making it incredibly expensive to process very long documents, high-resolution images, or genomic data.
For years, researchers have sought a successor—an architecture that could match the Transformer's performance without its quadratic scaling problem. A leading contender has now emerged from an unlikely source: classical control theory. State Space Models (SSMs) are making a dramatic entrance into the world of deep learning, promising linear-time complexity (O(N)) and highly efficient inference, challenging the Transformer's long-held dominance.
What is a State Space Model?

This sounds a lot like a Recurrent Neural Network (RNN), which also uses a hidden state to process sequences one token at a time. However, classic RNNs are difficult to parallelize, making them slow to train. SSMs possess a unique mathematical property that allows them to be expressed not only as a sequential recurrence but also as a global convolution. This dual nature means they can be trained in parallel like a CNN, but run inference sequentially and efficiently like an RNN, giving them the best of both worlds.
The Innovation in Mamba's Selective Architecture
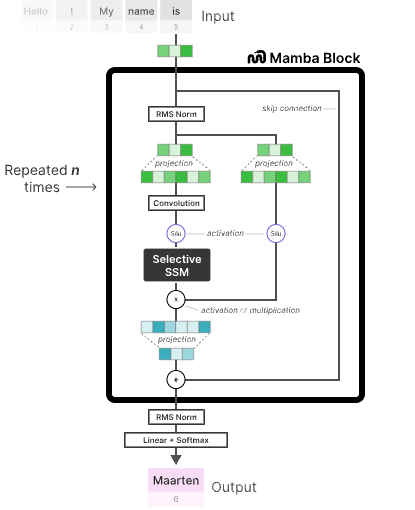
Early attempts to use SSMs in deep learning showed promise but couldn't quite match the context-aware reasoning of attention. They were good at capturing global patterns but struggled to focus on specific, important tokens. This changed with the introduction of "selective" SSMs, most famously exemplified by the Mamba architecture.
The key innovation in Mamba is that its parameters are not static; they are functions of the input data. In a classic SSM, the matrices that govern how the state is updated (A, B, C) are fixed after training. In Mamba, these matrices are generated dynamically for each input token.
This "selection mechanism" allows the model to be content-aware. Based on the current token, the model can decide to either remember information by passing it through its state, or forget it by flushing the state. This gives SSMs the ability to selectively focus on or ignore parts of the sequence, effectively mimicking the context-dependent behavior of self-attention without the quadratic cost.
Comparing SSMs and Transformers
The rise of SSMs creates a new architectural trade-off for AI practitioners. While Transformers remain incredibly powerful and well-understood, SSMs present a compelling alternative, especially in specific domains.
| Aspect | Transformers (Attention) | State Space Models (Mamba) |
|---|---|---|
| Complexity | O(N²) (Quadratic) with sequence length. | O(N) (Linear) with sequence length. |
| Training | Highly parallelizable. | Also highly parallelizable (as a convolution). |
| Inference Speed | Slow and memory-intensive due to a large key-value cache. | Extremely fast; state is constant-size, no cache needed. |
| Long-Context Ability | Struggles with very long sequences due to cost. | Excels at long sequences (1M+ tokens). |
| Expressiveness | Unrestricted, can model any token-to-token relationship. | Theoretically more constrained, but highly effective in practice. |
The Future is Hybrid
The emergence of SSMs does not necessarily mean the end of the Transformer era. In fact, the most promising path forward appears to be a hybrid one. Models like Jamba (from AI21 Labs) have demonstrated the power of combining both architectural styles. By interleaving Transformer blocks with Mamba blocks, these models can leverage the strengths of each. The attention layers can handle complex, short-range patterns, while the SSM layers can efficiently manage long-range dependencies across the entire context.
This hybrid approach allows models to achieve a new and better trade-off between performance and efficiency. It suggests that the future of AI architecture may not be a single, monolithic design, but a flexible toolkit of specialized layers.
While the Transformer laid the foundation for modern AI, SSMs represent a significant new pillar. They solve the long-standing problem of quadratic scaling and have unlocked new capabilities in long-context reasoning. As research continues, these efficient and powerful sequence models are poised to become a critical component in the next generation of artificial intelligence.
Enjoyed this post? Subscribe to the Newsletter for more deep dives into ML infrastructure, interpretibility, and applied AI engineering or check out other posts at Deeper Thoughts